
Corpus Linguistics: Method, Analysis, Interpretation.
Table of Contents
Week 1.
Why use a Corpus.
{kind=link}
- large amount of data dealing with.
- instances of very (|& not necessarily but as for our state of art itself) (rare exceptional) cases that we would not get from looking at single texts or introspection.
- Human: make mistakes & are slow; Computers are much quicker & accurate.
Resources
-#LancsBox Weeks 1-4 Got it at ~/Software/LancsBox ; load it by clicking on the *jar executable, a how-it-works tutorial here
- Getting starting:
Usage (in the case of jar files)
$java [-options] -jar jarfile [args...]
So (to execute a jar file) cd to the LancsBox dir and:
$java -d64 -jar LancsBox
- http://corpora.lancs.ac.uk/lancsbox/materials.php
- Intro to Corpus Statistics break at 25:30 min
stopped at 1.9, 2:20 out of 07:41 https://www.futurelearn.com/courses/corpus-linguistics/5/steps/149218
(Part 5) Corpora & Language teaching.
textbooks, dictionaries, classroom exercises, tests, learner corpora. Why or how come? Corpora give us great evidence about concordance, collocation, etc. But sometimes it doesn't give us the explanation, because the explanation is outside the corpus. Recommended readings on this topic: Susan Hunston's book, available in your course library. Corporate and Applied Linguistics. Chapter 1 in particular. & McEnery and Wilson, Chapter 1, which is available on the website..
- Learning from The Spoken Corpus project & trying it with. Otherwise, a useful how-to querying PDF. Though, for a quick searching anything better than my-sketch-engine, yet.
Lenguage Matters & Spoken English in Today's Britain conf.
- types of corpora? Monolingual/multilingual, parallel/comparable,comparative corpora.
- McEnery, T. and Wilson, A. (2001) Corpus Linguistics, Edinburgh University Press, Edinburgh.
- useful quotes: "Corpus linguistics is perhaps best described for the moment in simple terms as the study of language based on examples of 'real life' language use." "Chomsky changed the object of linguistic enquiry.. linguistic must seek to model language competence rather than performance" "The corpus has the benefit of rendering public the point of view used to support a theory. Corpus-based observations are intrinsically more verifiable than introspectively based judgments."
Week 2.
- Collocation & Keywords (2 techniques that are core to the corpus linguistics enterprise)
- quoting: "Where there's this strong affinity between a word and a particular grammatical class, for example, we often call that colligation. And distinguish that apart from collocation, which is more associated directly with meaning, rather than grammar (…) So for example, "he" colligates with verbs, "Mrs" colligates with proper nouns and determiners colligate with nouns."
Part 3 (Keywords) "Chi-square or log-likelihood, for example, are two statistical significance tests which allow you to demonstrate that a certain word in corpus
Ais more frequent in a way that is statistically significant than it is in corpusB"
Week 3.
Stuck as an chronic-illness-by affected one about finding the perfect LISP based NPL toolkit (and after exhausting (again) & exhausted of some (by me, at least) very known old tutorials) whose visual performance would look like this screenshot I'm not only decided to switch to python environment (specially after learnt that the-most-updated-LISP-based-NPL-toolkit-of developer I was on a deep worship was just bringing up to LISP software already made in python) but I found that a py script I did time ago when gaining myself literacy on that language, was just for-my-purposes, enough, simpler & more efficient. So, get finishing of searching for a greener grass, please.
{kind=link}
{kind=link}
- Anyway, here I list some readings on shell for linguistics approach to this subject for a self paced review to get completed, so as some-day project list.
- 11. Extended reading
– egrep for linguists by Nikolaj Lindberg, STTS Södermalms talteknologiservice. (Highly recommended!)
– grep for linguists by Stuart Robinson.
– Text Processing Using Unix CLI (looking for the previous one above I found the latter, so interesting, though including some already mentioned (& got in usage) tips)
– Unix™ for Poets by Kenneth Ward Church, AT&T Bell Laboratories. (The ultimate manual which I am still learning it.) https://web.stanford.edu/class/cs124/kwc-unix-for-poets.pdf
– Ngrams by Kenneth Ward Church, AT&T Bell Laboratories.
– The Awk Programming Language by Alfred V. Aho, Brian W. Kernighan, and Peter J. Weinberger. (An old staff, but rather handy and comprehensive!)
– Why you should learn just a little Awk - A Tutorial by Example by Greg Grothaus, Google.
– Unix Shell Text Processing Tutorial (grep, cat, awk, sort, uniq) by Xah Lee
– Sculpting text with regex, grep, sed, awk, emacs and vim by Matt Might, University of Utah.
- 11. Extended reading
Note aside, while reading up about UNIX for linguistics stuff, I ran into a book I'd known about, a so strange bibliographic piece one, actually, I got a copy. What I didn't know, so silly of me, it's that there is out there a so old and quite rooted tradition on connecting art & computation, I'd call it as.
Week 4.
Building a Corpus. So, We also could build a corpus from news. Interesting indeed, so meant keep it documented to, I should annotate 2 points, (first) the core clip (here if webm ogg if so) about how-to operate with the online exploring corpora interface, and (2) the bbc.news website as it's suggested, could be a good source of data.
- Hey, I (almost) forgot those some error handling considerations about playing mp4/webm/ogg files. So find attached the
ffmpegcommand to convert it to..$ ffmpeg [global options] [input file options] -i input-file-name [output options] output-file-name
So, applied it gets:
$ ffmpeg -i input-file.mp4 -c:v libvpx -crf 10 -b:v 1M -c:a libvorbis output-file.webm
If it's about —play it in
*.oggfile, Sam:$ ffmpeg -i input.mp4 -acodec libvorbis -qscale:a 5 -vcodec libtheora -qscale:v 7 output.ogg
Well, let's try to (alternatively) embed those video documents above mentioned straight in this, my Org-mode course notepad, by including a <#+[begin|end]_HTML source code block and embed a video frame as explained here, so have to everything handy.
- Touched, yeah, by this storm of reading on words as data, its colligation & collocation pattern & issues I ran into a so strange living activity as it is inventing language itself (& using in the filming industry so successfully)
Week 5.
Corpus Methods in Forensic Linguistics, the Derek Bentley case. Explained as done in the correspondent lecture got it clearly what powerful it could become as method or toolkit.
- An extensive tutorial about the online cqpweb corpora engine, quite useful especially on the chapter related making restrictions when searching collocation over different corpora sources.
Week 6.
I should highlight straight W.6-part 8, "citing examples.." because it was guessing cases for rules I were on & digging in those subtle meaning behind everything, the context of my great encounter with the corpora (I found out, almost immediately, this was a quite more versatile learning language tool, indeed, than anything I'd tried so then. It was more efficient giving me such a more great deal of examples than the most caring or involved of my teachers. So, once got into that new mind window I never looked back anymore. I should mention, however some extras this course & inc. tools bring up :
- —part-of-speech tag
pst(seen e.g. in 6.18 & here, accessed usually using the underscore character "_"). & following the formword_pstas in this example:strange_adjso it'll search in that particular corpora, otherwise error rate, for excerpts of speech where "strange" appeared asadjective. Things checking for- the tag set, here (under Corpus info): the CLAWS7 tagset, a software which has 150-odd tags in it. Good for disambiguating searches, e.g.
VVNfor (normal) past participle.
- the tag set, here (under Corpus info): the CLAWS7 tagset, a software which has 150-odd tags in it. Good for disambiguating searches, e.g.
- Getting access to a second level annotation using some regex characters:
?,*,?*suffix(as with:?*ableor "??+*able|suffix" when precise e.g. +3 chars before a given suffix). Also as in this next instance "capab[le,ility,ilities]" or "walk[s,ing, ]". - (see 6.20 looking for tertiary annotation (using here "The Oxford simplified tag set") e.g.
_(break/N)will look up for break as Noun, and so forth for e.g.Vverbs. - —similar when looking for phrases (6.21). & This case at, the use of wild cards & combination of them take the following forms:
(eat) up,(eat) * up,(eat) + up,(eat) +* up,(eat) +** up, also(go)[away|up|down|through] {be} _{ADV} _V?N{be} (_{ADV})? _V?N{be} (_{ADV})* _V?N{be} (_{ADV})+ _V?NSo got seen question mark, star, and plus. Question mark— zero or one of whatever is in the brackets before. Star— any number of what's in the brackets before, zero or more. And plus— one or more of whatever is in the brackets before.
Week 7.
The point theme here turns out to be a funny facility directly derived from the corpus itself as tool. As being able to narrow collecting data from specific language users o population & analyse behaving particularities, allow us to make specific inputs in accordance to particular (mistakes) frequency patterns, or, what basically is, built a Learner Corpora so increment the potential insight of inputs accordingly language background typical complexions. Justly because of this, there is, still, something more promising in this section & I'd want to output it raw: As we can get an privileged observer position about different fork views from a given grammar world, to that extent to, we are also able to study universal|human language structures, I am thinking of the Chomsky's universal grammar idea (I went, in a post, recently, funny to call it a grammar martian grammartian [point of view|approach])
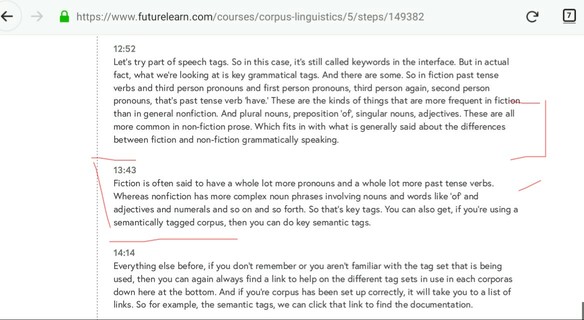
Figure 1: Some gram-tags usage patterns when reporting as fiction or general prose.
A global language (education) in its early stage..
From Data Driven learning DDL to Contrastive Inter-language Analysis CIA, or variation in inter-language studies, or foreign language theory & practice (& how come this all) learner corpus research would point up to (my) gram-martian concept of (dealing with learning) language, where we also would have got a first (kind of) text-handbook.
Week 8
Some lectures this week remind me a time when I myself made a spoken English map which I used to call to "my 101 manners of saying-fuck list" I used to have a fun in my job spare time at crossing my list with new items as I was able to excerpt & tag them from my work mates conversation, now I got a entire corpus for explore on it, the LCA (Lancaster Corpus of Abuse, week.8.part1:Looking-at-bad-language)
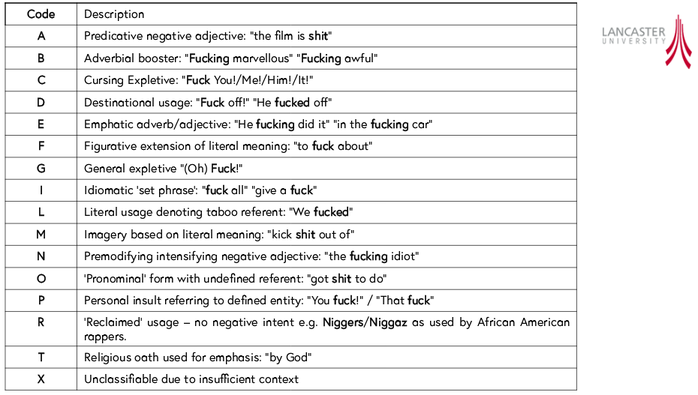
Figure 2: Here some fucking useful code tags.
- & The "looking-at-bad-language lecture" part 1.
Hey, while on exploring and filtering on spoken corpus, the starring tool of this week is this online tool designed for corpus-based sociolinguistic analyses http://corpora.lancs.ac.uk/bnc64/